常常看到一些总结,比如HashSet允许Null值,HashTable则不允许。死记硬背固然可以,但是根据艾宾浩斯遗忘曲线,对于不理解原理的知识我们总是最快遗忘的。正好最近在看集合框架相关的源码,所以想整理分享出来。
整个集合框架代码量非常大,如果事无巨细的全部罗列非常耗时,而且仍然避免不了看完就忘。针对集合类的特点,准备这样进行整理。首先以一个具体类为切入点,说明它的继承关系。接着,说明这个类内部的存储结构,比如HashMap,就说明它内部是怎么实现元素的存储和各种操作的。最后,回到文初提到的那些总结,从源码角度说明HashTable是怎么实现不允许Null值插入的。通过这样的学习过程,我们应该就会对这些集合类的重点了如指掌了。
HashSet
HashSet是什么
HashSet的本质是一个Set。Set的就是一类数据的集合,并且内部的数据不能重复。
HashSet的继承关系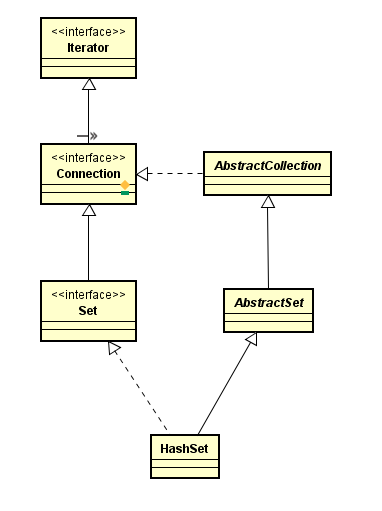
HashSet继承自AbstractSet类并实现了Set接口。
HashSet的内部实现
首先看一下HashSet的构造函数
|
|
在HashSet的构造函数中,新建了一个initialCapacity大小的HashMap。
再看HashSet的add方法,代码如下
|
|
其实就是在刚才构造函数中新建的HashMap中插入了一个Key值,而PRESENT其实是
所以HashSet的所有元素都是在其内部成员变量HashMap的Key中进行储存和管理,而这些Key的Value其实都一样,就是一个Object()。
如此一来,就可以理解了,对HashSet的插入和删除等操作,都可以通过这个map的方法进行管理,可以看一下其他操作的一些实现。
那些难背的特性
开头的时候说了HashSet允许Null值但不允许重复的值。
HashSet的内部实现是一个HashMap的Key值存储的,所以问题转化为了HashMap的Key值是允许Null值但不允许重复的值。那接下来就看HashMap吧。
HashMap
HashMap是什么
HashMap的本质是一个Map。Map的就是一类键值对数据的集合,它有如下的特性。
- Key值不能重复
- Key值和Value值可以为Null
HashMap的继承关系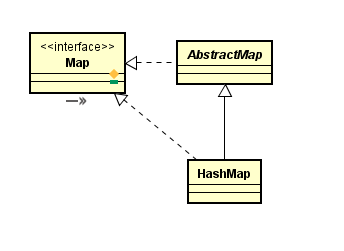
HashMap继承自AbstractMap并实现了Map接口。
HashMap的内部实现
首先看一下HashMap的构造函数
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key);
int i = indexFor(hash, table.length);
for (HashMapEntry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
|
|
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
// Android-changed: Replace usage of Math.min() here because this method is
// called from the <clinit> of runtime, at which point the native libraries
// needed by Float.* might not be loaded.
float thresholdFloat = capacity * loadFactor;
if (thresholdFloat > MAXIMUM_CAPACITY + 1) {
thresholdFloat = MAXIMUM_CAPACITY + 1;
}
threshold = (int) thresholdFloat;
table = new HashMapEntry[capacity];
}
|
|
static class HashMapEntry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
HashMapEntry<K,V> next;
int hash;
/**
* Creates new entry.
*/
HashMapEntry(int h, K k, V v, HashMapEntry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
...
}
|
|
private V putForNullKey(V value) {
for (HashMapEntry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
|
|
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new HashtableEntry[initialCapacity];
threshold = (initialCapacity <= MAX_ARRAY_SIZE + 1) ? initialCapacity : MAX_ARRAY_SIZE + 1;
}
|
|
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
HashtableEntry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
...
}
```
当value为null时会抛出空指针异常,如果key为null呢,似乎没有处理。其实,在下面去key的hash值时,hash(key)的实现会调用key.hashCode(),可想而知如果key为null在这边就会因为空指针程序异常退出了。所以HashTable是不允许插入key或者value为null的元素的。
总结
这一次我们从源码角度分析了HashSet,HashMap,HashTable的内部存储结构和一些特性的原理解释,相信大家对这些概念的理解应该不只是停留在文字层面了。本篇初版暂时写这么多,后续有补充的话再进行更新。